
Ergoweb Enterprise™ Software

Simple to Use
Comes with a library of industry-standard ergonomics design, assessment and improvement tools and guidance on when and how to use them.
Easy to Adopt
Turn-key systems for employers new to ergonomics, and configurable systems for expanding or mature ergonomics programs.
Streamlined Reporting
Rapidly generate management reports to track KPI’s, assessments, improvements, and action items.
From the Learning Center
February 2, 2022
Article Highlights: Fatigue Failure theory is a new ergonomics theory about how workers develop MSDs Three recently developed ergonomics assessment tools — LiFFT, DUET and The […]
July 16, 2021
Liberty Mutual Insurance Company has conducted numerous studies over several decades that help identify and reduce risk of injury related to manual material tasks like lifting, […]
May 13, 2020
The COVID-19 pandemic has forced many employees to stay home, and others to work reduced schedules. This extended time away from work may result in some […]
Downloadable Guides

5 Essential Elements of a Successful Ergonomics Process
This 14 page guide explains 5 essential elements successful ergonomics programs share, including ...

Guide to Establishing a Successful Site Ergonomics Process
This 10 page guide is for individuals or teams responsible for establishing a systematic workplace ergonomics program and processes at a company site or facility.
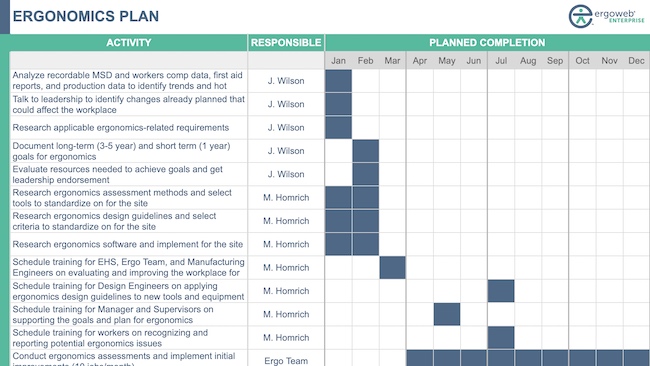
Site Ergonomics Planning Template
This spreadsheet contains 6 template sheets you can edit to expedite planning and gain approvals for a site ergonomics process. The download also includes ...